Practical Data Science: How to Easily Rank in Kaggle Beginner NLP Competition Using sklearn

Introduction
Kaggle is an online community and data science competition platform for data scientists, machine learning engineers, and data analysts, featuring many rewarded data science competitions and datasets. The Kaggle community is very famous in the data science field, with many major internet companies publishing rewarded competitions with prizes ranging from tens of thousands to millions of dollars. This article introduces a recent participation in a Kaggle beginner NLP competition, which has no cash rewards but allows learning NLP-related machine learning knowledge.
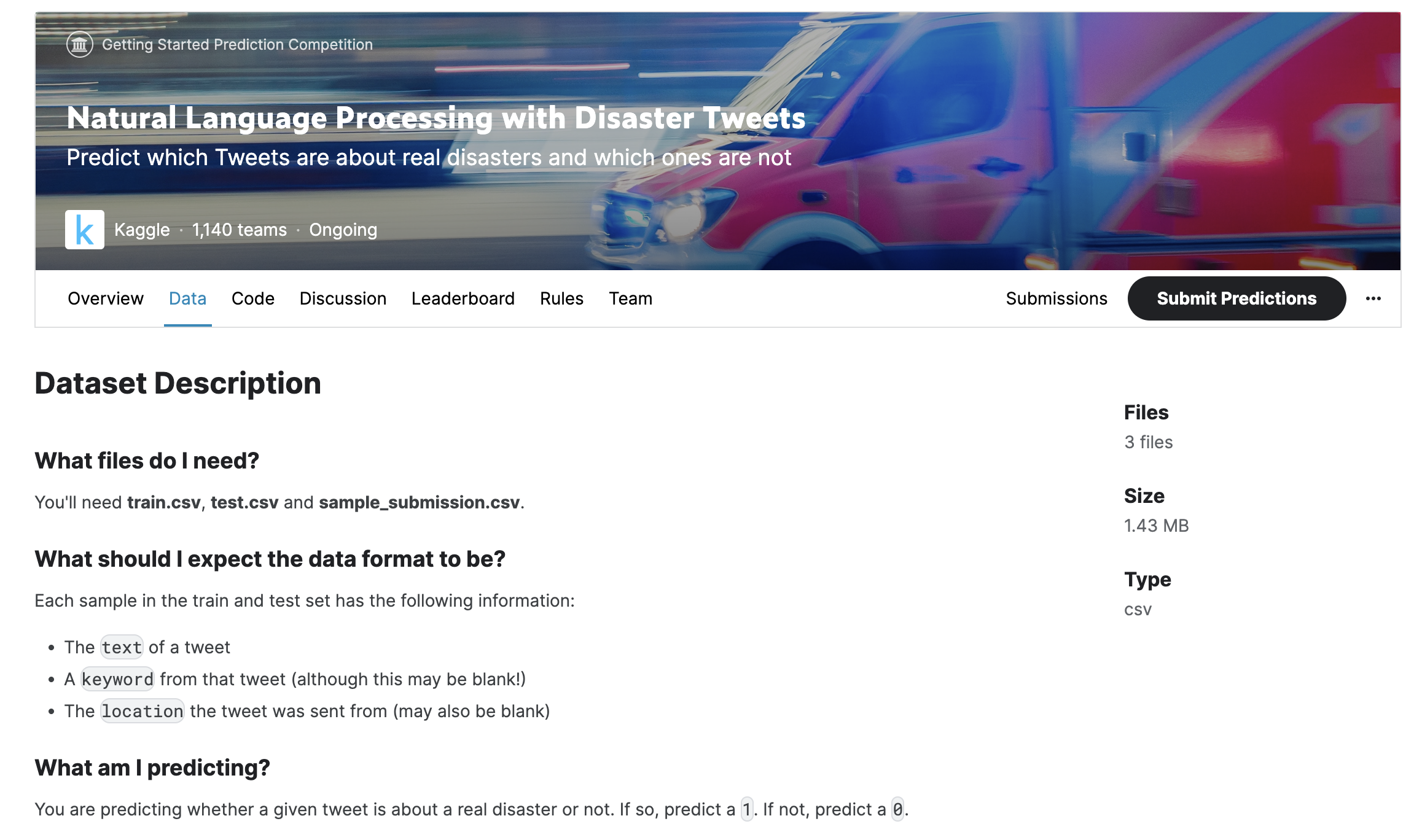
Competition Overview
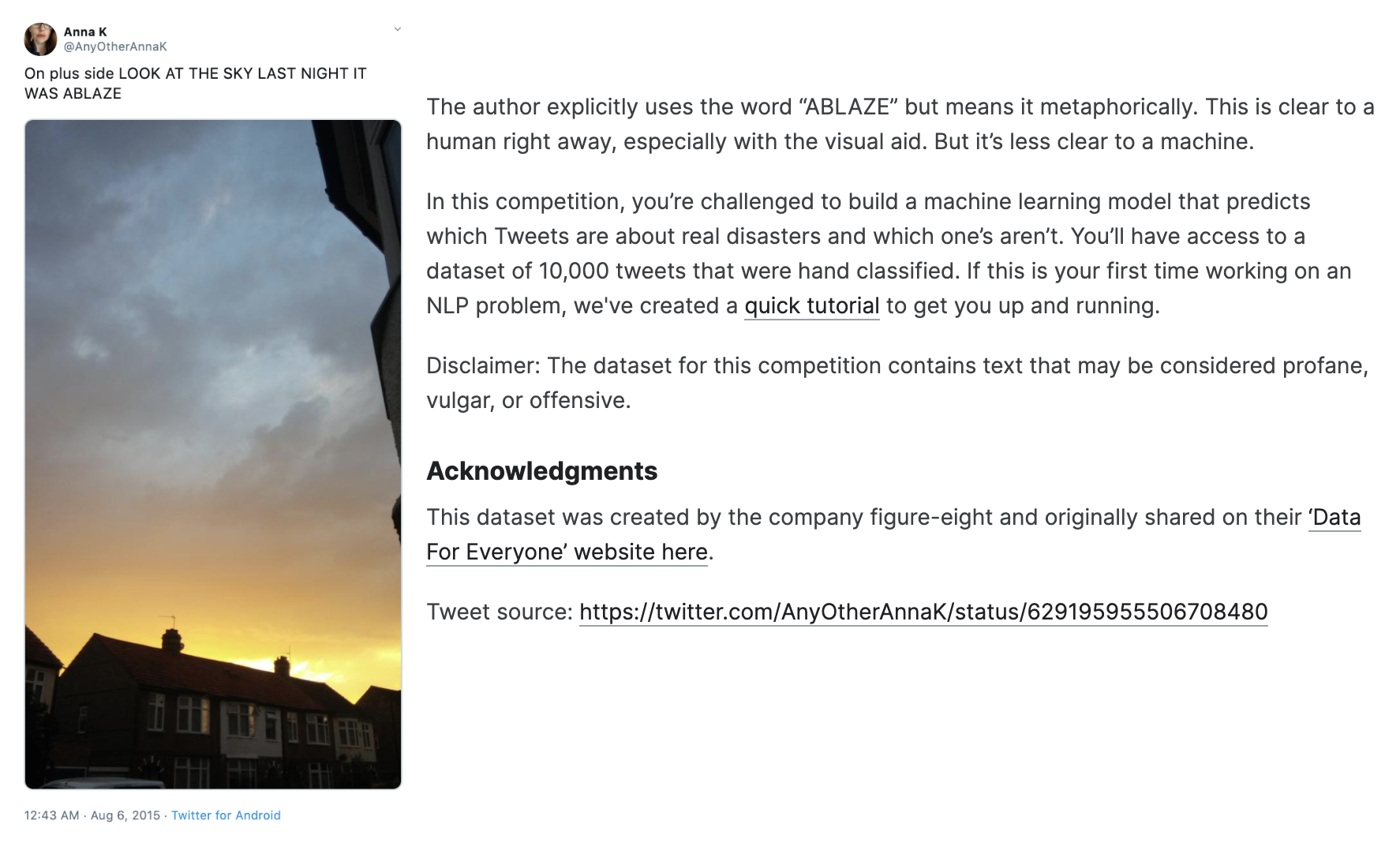
This data science competition asks participants to determine whether a tweet is about a real disaster based on a given Twitter tweet. The image below shows a particular tweet containing the keyword "ABLAZE," indicating the tweet is about a house catching fire.