Cybernetics and AI Agents: A Forgotten Old Language

A team of eight engineers has wired AI coding agents into their development pipeline. The agents take tickets off the top of the queue and ship pull requests faster than humans can review them. Six months in, the dashboards look enviable. Test coverage sits at 84%. The p99 latency on every changed endpoint stays under 100 ms. Merge throughput is up 3× since the agents went live. The Friday retrospective is short, because there is little to retrospect on.
Then a competitor ships a feature. It is not a clever feature. Their users had been asking for it on a public forum for six months, and the team's own users had been asking for it on the team's own forum for almost as long. No one on the team noticed. The competitor's launch lands in Slack on a Tuesday, and the room goes quiet, because everyone is asking the same question at once: which part of our system was supposed to catch this?
The honest answer is: no part. Not because someone forgot to build it, but because the team's architecture vocabulary has no word for it.
Layered, microservices, hexagonal, DDD — the four dominant architecture languages all answer the same question: how is the code partitioned? None has a word for the question the team asked on Tuesday: how does this system, as an organisation, stay alive? That question has always been answered, but in the human org around the code: PMs and scrum masters ran the schedule, SRE and QA ran the audit, product watched the market, executives set direction, incident responders pulled the alarm. The architecture languages didn't need vocabulary for any of this because the org chart absorbed it.
Cybernetics named those parts fifty years ago, then software discourse forgot the vocabulary. AI agent systems are making the question impossible to keep avoiding: when agents take over the operational layer, the human layer can't stretch fast enough to cover the surface it used to absorb. The Viable System Model is the diagnostic mirror best suited to this moment.
A brief history of cybernetics
The vocabulary in question came together quickly, in a forty-year arc that touched three disciplines. Norbert Wiener's Cybernetics (1948) lifted the engineer's idea of feedback out of servomechanism design and applied it across biology, neurology, sociology, and machinery at once. The book's subtitle — Control and Communication in the Animal and the Machine — was a deliberate provocation. Wiener was claiming that the same mathematics describing how a thermostat regulates a room could describe how a pancreas regulates blood sugar, how a market regulates prices, and how an organisation regulates its own conduct. The claim was controversial at the time and is now, half a century later, mostly absorbed into common scientific intuition. Its operational consequence is that feedback — the routing of a system's outputs back to its inputs — is the primitive operation by which any system, of any substance, holds itself together.
Wiener pointed in a direction. W. Ross Ashby, eight years later, drew the first hard constraint. An Introduction to Cybernetics (1956) introduced the Law of Requisite Variety, which Ashby stated with characteristic compression: only variety can destroy variety. If a system can be in N distinct states under disturbance, its controller must itself be capable of N distinct responses; anything less, and there exist disturbances the controller cannot absorb. This sounds abstract; it is not. A monitoring system with three alert levels cannot meaningfully distinguish among twenty different failure modes. A code review checklist with five questions cannot meaningfully review a pull request that creates twenty different kinds of risk. The variety of the controller must at least match the variety of what it controls, or the controller is a placebo. This is the quantitative floor below which no regulator can fall, regardless of how clever its internal logic is.
Ashby's law tells you the controller must be big enough. It does not tell you what the controller must look like. The structural companion came fourteen years later, in a short paper Ashby co-wrote with Roger Conant. Every Good Regulator of a System Must Be a Model of That System (1970) is one of the most consequential one-sentence titles in the cybernetic literature. The theorem proves that a regulator of any sufficient power must contain internal structure that mirrors — is a model of — the system it controls. Pre-stored response tables are not enough. Lookup-based reactions are not enough. The regulator must have, somewhere inside it, a representation of how the controlled system actually works, or it cannot achieve good regulation in the formal sense. Ashby's law answers how big; Conant-Ashby answers what shape. The two together exhaust the space of formal requirements for any controller — and, as §5 will show, they are the constraints that bound every harness around a language model.
Cybernetics could have stayed a mathematical discipline. Stafford Beer took it sideways, into the management of organisations, starting in the late 1950s. His central question — what does it take for an organisation to be viable, to remain itself, under sustained disturbance from its environment? — was the Ashbyan question one ladder up. Brain of the Firm (1972) gave the first complete statement of the Viable System Model, a structural decomposition of any viable organisation into five recursively nested subsystems, plus an audit channel and an alarm channel. Diagnosing the System for Organizations (1985) refined the model and added the diagnostic stance that is the main reason the framework is useful today: VSM is not a blueprint to copy but a mirror to hold up against an organisation — a checklist of parts that must exist somewhere. Beer's contention was that an organisation missing any of these subsystems is not unhealthy. It is structurally precluded from staying alive under variety it has not already absorbed.

Figure 1: The cybernetic lineage in four works. Each one extends what the previous one couldn't quite reach — feedback as the primitive operation; how much control a system needs; what shape the control has to take; how it lives at organisational scale.
Cybernetics does not ask what is the system made of. It asks how does the system preserve its identity under disturbance. That second question is what software architecture, for the last two decades, has not been asking — and what AI agent systems make it impossible to keep avoiding.
The five VSM levels — and what an AI-agent pipeline looks like through them
VSM decomposes any viable organisation into five subsystems plus two side channels. The five subsystems form a vertical stack from raw execution at the bottom to identity at the top; the audit channel watches one subsystem laterally, and the alarm channel cuts vertically from bottom to top, bypassing everything between. Beer's Brain of the Firm (1972) and Diagnosing the System for Organizations (1985) walk through both layers in detail. The translation that follows takes each level twice: first as it has historically lived in a software organisation, then as it shows up in a development pipeline running AI coding agents.

Figure 2: The Viable System Model with algedonic channel. Each level is shown as it has historically lived in an engineering team (left column) and as it shows up in a pipeline running AI coding agents (right column). S3* is drawn as a parallel side channel — not a subordinate of S3 — and the algedonic path runs vertically from S1 directly to S5, bypassing everything between.
S1 — Operations
S1 is the executing unit, the part of the organisation that does the actual work. A viable system always has more than one S1 — the model assumes operational diversity — and each S1 is itself a viable system one level of recursion down. In a traditional engineering team, S1 is the developer writing code, the test running, the deploy executing. In an agent-driven pipeline, S1 is the individual agent session: a single coding-agent invocation that picks a ticket off the queue and produces a pull request. Each session is self-contained, has its own context window, and produces a discrete artefact that can be inspected. The team in §1 had S1 covered: agents shipped PRs all day long.
S2 — Coordination
S2 keeps S1 units from clobbering each other. In Beer's terms, it dampens oscillation between operations that share resources or have to act in sequence. In a traditional engineering team, S2 lives in branch policies, the PR review queue, paired-programming protocols, and the unspoken rule that you do not push to main without telling someone. In an agent-driven pipeline, S2 is the technical isolation that lets multiple agent sessions run without trampling each other's state: separate git worktrees, sandboxed runtimes, request-scoped database fixtures, locking primitives around shared write paths. The team in §1 had S2 covered too — without it, two agents touching the same file in parallel would have produced merge chaos no dashboard could have hidden.
S3 — Control
S3 is the here-and-now management of operations: scheduling, resource allocation, supervision, immediate intervention when something goes off. In a traditional engineering team, S3 is the scrum master and the engineering manager — standups, sprint planning, capacity allocation, blocker resolution. In an agent-driven pipeline, S3 is the layer that decides which session works on which ticket and at what priority: the DAG planner, the work-allocation policy, the session triage that escalates when a PR has been open too long. S3 is what most engineering leaders mean when they say we need better tooling around the agents — and the team in §1 had this layer, in the form of a routing system that fed tickets to the most appropriate agent on any given day.
S3* — Audit
S3* is the side channel that watches S3 itself, looking for systematic drift S3 cannot see in its own mirror. In a traditional engineering team, S3* is SRE on the operational side, QA on the product side, and security review on the access side — disciplines deliberately outside the regular reporting chain. In an agent-driven pipeline, S3* is the audit that watches whether the routing system, the planner, and the supervisors are doing what they claim — independent of the people running them. The crucial structural property of S3*, which §4 will return to, is that it must reach S3 bypassing S3's own channels. An audit the audited subsystem can rewrite is not an audit.
S4 — Intelligence
S4 looks outward and forward: scanning the environment, modelling possible futures, surfacing things that are not yet on anyone's backlog. In a traditional engineering team, S4 is product management, user research, sales intelligence, customer success, and competitive analysis. It is rarely a single role; it is a function, distributed across people whose job is to translate the world outside the team into work inside it. In an agent-driven pipeline, S4 is — almost always — the part that does not exist. Most pipelines can digest tickets that already sit in JIRA. Few have any organ for noticing what should be in JIRA but isn't. The team's competitor-feature blind spot in §1 was not an S1 failure or an S3 failure. It was an S4 vacancy.
S5 — Policy
S5 is identity and purpose: the unfalsifiable commitments that say what the system is and what it is for. S5 is not a rulebook; it is closer to a constitution — the small set of statements that define what kind of organisation this is, and against which proposed actions can be measured. In a traditional engineering team, S5 lives in founder statements, company values documents, the executive's recurring all-hands talking points, and — for engineers — in artefacts like AGENTS.md, CLAUDE.md, principles documents, and architectural decision records. Lightweight spec frameworks are one attempt to give these commitments a stable home in the repo. In an agent-driven pipeline, S5 lives wherever the pipeline's purpose has been written down with enough clarity that an agent can be expected to act consistently with it. When S5 is missing, metrics fill the vacuum: we ship fast becomes the de facto identity, because that is the only thing the dashboards can measure.
The algedonic channel
The algedonic channel is the direct vertical line from S1 to S5 that bypasses S2, S3, and S4 entirely. Beer named it from Greek algos (pain) and hedone (pleasure): the alarm path. It exists because some signals are too urgent, or too systemically important, to make their way up through the regular reporting hierarchy. In a traditional engineering team, the algedonic is the on-call page, the security incident escalation, the customer-success crisis call that lands in the CEO's inbox without going through three managers. In an agent-driven pipeline, the algedonic channel is the layer that fires when something the system was not designed to recognise has nonetheless become visible — a class of failure no metric covers, an external signal no S4 was watching for. The team in §1 did not have one; the gap between what we ship and what users actually need would have opened anyway, but a working algedonic channel would have surfaced it long before a competitor's launch landed in Slack.
Three counterintuitive points
The walkthrough above gives a vocabulary. The three diagnostic heuristics below say what you tend to see in real software organisations once you can use that vocabulary. None sounds dramatic on its own. Together they explain most of the failure modes engineering leaders have learned to recognise but have not learned to name.
1. The absence of S4 is the default, not the anomaly
Most software organisations operate without a complete S4, and many operate without a complete S3 either. The system has no awareness of its environment is not a defect; it is the norm. The reason is that S4 is expensive — it requires people whose full-time work is to look outside the team and turn what they see into proposals the team can act on. When budgets are tight, S4 is the first function cut, because the work S4 produces does not show up on a dashboard until the absence of it does.
The §1 scenario is a clean instance of this. The team had S1, S2, and S3. Audit existed in some form. Identity was implicit. But there was no organ pointed at the outside world. The competitor's feature was visible on a public forum for six months; nobody on the team had the job of seeing it. This is not unusual — industry surveys of stalled AI-agent deployments find environmental blindness near the top of the failure list, and the same pattern shows up across the broader 2026 agent landscape. Most agent pipelines can digest what already sits in the backlog; few have any way of noticing what should enter the backlog in the first place. If you remember one thing from this article, it should be this: S4 absence is the modal failure mode of software organisations, and agent-driven pipelines inherit it by default.
2. S3* cannot be absorbed by S3
The audit channel must run alongside S3, not through it. The moment an audit signal has to traverse the subsystem it is meant to audit, it stops being an audit and becomes a self-report. This is why SRE on the operational side, QA on the product side, and security review on the access side are routinely deployed outside the engineering reporting chain — Google's own SRE journey writeup is explicit that "SRE and developer organisations share common goals and may have separate reporting chains up to SVP level or higher" — not because the people running them want their own dashboards, but because the audit function structurally requires independence. Teams that consolidate SRE under engineering management or security under platform routinely discover, six months later, that the audit they thought they had is in fact a self-report with extra headcount.
In an agent-driven pipeline the same constraint applies, and it tightens. The system that audits the agents must not share state with the routing system the agents go through. The system that audits the planner must not be configurable by the planner. The system that audits how prompts evolve must read from a write path the agent layer cannot reach. These are not nice-to-haves. An audit subsystem the audited layer can rewrite — even indirectly — is a placebo, and placebos are worse than no audit at all because they offer cover for problems that do exist.
3. S5 is unfalsifiable commitment, not if-then rules
"We are a low-latency system" is S5. "Alert if p99 latency exceeds 100 ms" is one instantiation of that commitment at S3. The two levels are not interchangeable, and the difference is what the next section is about. A commitment names what the system is; a rule names a single observable check. A commitment can survive the failure of any individual check; a rule cannot survive a change in the underlying landscape. Conflating the two — replacing the commitment with the rule — is the most common architectural mistake in organisations trying to operationalise their values. It is also the mistake that AI-governance frameworks built on hard-rule content filters keep making, and the next section spells out exactly why this failure is structurally guaranteed.
Why a projection isn't a model
The third counterintuitive point — that S5 commitment is not S3 rule — sounds at first like stylistic guidance, the sort of thing reasonable people might disagree about. It is not. Two results from cybernetics plus one from economics, taken together, show that operating a system from rules alone, without an underlying commitment, is not merely poor practice but structurally precluded.
Two theorems, one constraint
§2 introduced the two results separately. They are best understood together.
Ashby's Law of Requisite Variety sets the quantitative floor: a controller's variety must be at least as large as the variety of what it controls, or there exist disturbances the controller cannot absorb. Conant-Ashby sets the structural floor: a controller of any sufficient power must have internal structure that mirrors the system it controls — must, in the precise sense of the theorem, be a model of it. Ashby tells you how big the controller has to be. Conant-Ashby tells you what shape it has to take. A controller large enough but unstructured fails by Conant-Ashby; a controller well-structured but too small fails by Ashby. Both constraints have to hold simultaneously; either one alone is insufficient.
Models versus measurements
The clearest way to see what Conant-Ashby requires is not through the formalism. It is through three everyday objects.
A scale reading is a projection of body composition. You step on the scale, the number drops, and the silhouette in the mirror often does not change. The scale is useful. It is not body composition.
A salary is a projection of financial freedom. Two engineers earning the same number can have wildly different freedoms — different debt loads, different costs of living, different passive incomes, different degrees of control over their own time. The salary is useful. It is not freedom.
Years of tenure is a projection of experience. Fourteen years at one company can mean fourteen years of compounded growth, or year one repeated fourteen times. Tenure is useful. It is not experience.
The pattern is the same in all three: a single number that compresses a structured object down to a value on a single axis. The number is real, it is useful, and it is not the thing. Call the kind of compression that preserves the shape of the system structural compression. Call the kind that flattens the system onto a single axis projective compression. Both are useful. The error is treating the projection as if it were the structure.
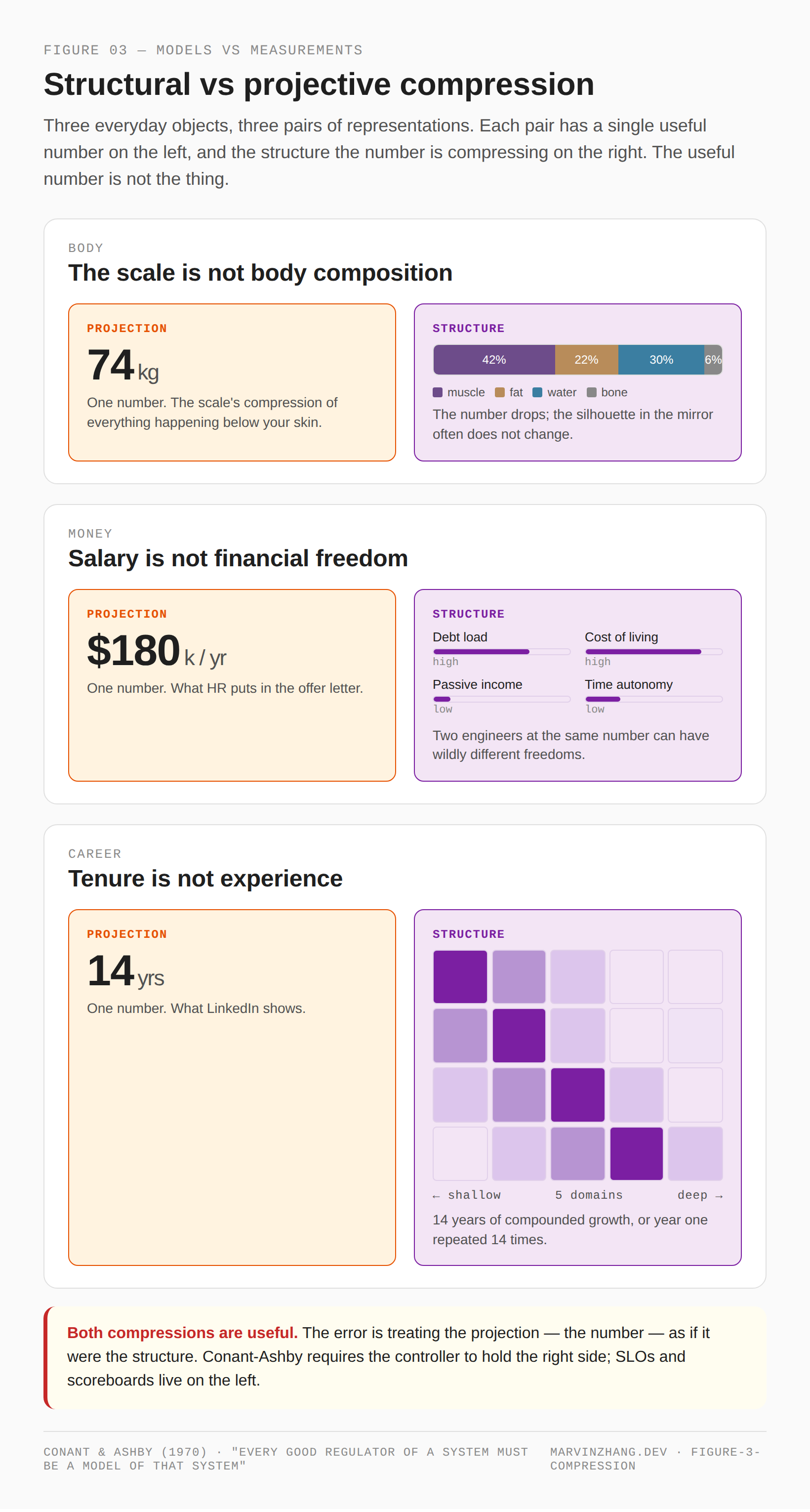
Figure 3: Body, money, career — three everyday objects, each as a projection (left, a single number) and as the structure that number was compressing (right). The structure is what a controller can actually regulate; the projection is what shows up on a dashboard.
Conant-Ashby says, in this language, that a regulator must hold a structural compression of the system it regulates — not just a projection. A control loop driven by body weight is not a regulator of body composition. A management system driven by salary is not a regulator of financial freedom. A career system driven by tenure is not a regulator of experience. And — to anticipate the payoff — a software system driven by SLO dashboards is not a regulator of what the system is for.
Goodhart's Law as the named failure mode
The mechanism by which projection-driven control fails has a name. Charles Goodhart, in a 1975 paper on UK monetary policy, observed that any statistical regularity central banks tried to exploit for control would tend to collapse once policy started pushing on it. Marilyn Strathern, in a 1997 essay on university audit culture, gave the formulation that has stuck in the popular memory: when a measure becomes a target, it ceases to be a good measure.
The hard engineering rules every team has lived with for the last decade are textbook Goodhart.
- "Test coverage must exceed 80%" → engineers write
assert(True)to lift the line, andassert(True)is what gets shipped to production. - "p99 latency must stay under 100 ms" → slow requests get sampled out, dropped at the edge, or rerouted to a path with looser SLOs; the dashboard turns green, users still wait.
- "Every PR needs two approving reviewers" → reviewers rubber-stamp each other; the policy is satisfied, the code is unread.

Figure 4: A rule is set in good faith (top of each card). Engineers optimise for the rule (left). What ships is a green metric and an unchanged underlying problem (right). The pattern is structurally guaranteed once a projection becomes a target — a well-documented phenomenon the industry has been working through for years.
None of these rules was designed badly. Each is a projection — a single-axis compression of the underlying property the team cared about — being used as a target. Once a projection becomes a target, the system optimises for the projection, and the optimisation destroys the projection's value as a measurement. The harder the team pushes the metric, the further the underlying property drifts.
S5 cannot collapse into S3
The reason S5 cannot be replaced by S3 is now visible from two independent angles. Conant-Ashby forbids it: S5 is the structural compression of what the organisation is; S3 is one projective compression of that model onto one axis at one moment. A controller equipped only with the projection has no model, and therefore — by the theorem — cannot be a good regulator. Goodhart punishes any attempt to evade this: an organisation that tries to operate from projections alone discovers that the act of targeting them destroys their information value. The harder you optimise the proxy, the further the underlying property drifts.
The implication for AI agent systems is doubly sharp. Language models, in their current form, have no internal model of the system they are deployed to control — a Conant-Ashby violation. The standard mitigation — static rule sets, content filters, output validators, behaviour policies bolted on top — is projection used as target, a Goodhart vulnerability. Both failure modes are structural, not contingent. Harness engineering, when it works, builds models rather than walls: it constructs controllers whose internal structure mirrors the system being controlled, and uses metrics as diagnostic readouts rather than as objectives. VSM is what Conant-Ashby looks like for organisations. Harness engineering is what Conant-Ashby looks like for AI systems. Both are answers to a question the field has not yet learned to ask out loud.
- AI Agents: Engineering Over Intelligence — the architectural framing this article builds on.
- The Last Mile of AI Is Infrastructure, Not Intelligence — adjacent argument about where the bottleneck really sits.
- Mapping the 2026 AI Agent Landscape — broader context for where agent systems sit today.
- Why Your Code Reviews Are Failing (And How to Fix Them) — the two-reviewer Goodhart trap, in depth.
A work in progress
I am currently applying this framework to a project of my own — Onsager — that builds AI agent pipelines for software development. The biggest lesson has not been confirmation of VSM's completeness, but how visible the model makes what's missing. Two levels in particular — S4 and the algedonic channel, the ones most often dismissed as "not needed" — are precisely the ones whose absence reliably shows up later as the failure modes described in §4. The work is early, and what I have learned applies mainly to my own context, but the framework has been useful enough at the diagnostic stage that I want to flag it before the implementation post lands. That piece will come when it is ready.
In an era where components themselves have purpose, what we need is not a new architectural pattern but a forgotten old language.