控制论与 AI 智能体:那门被遗忘的旧语言

一个八人的工程师团队,把 AI 编程智能体(AI Coding Agents)接进了自己的开发流水线。智能体从队列顶端取走 JIRA 工单,提交合并请求的速度超过人工评审的速度。半年下来,仪表盘上的数字相当好看:测试覆盖率 84%,每个改动接口的 p99 延迟稳定在 100 毫秒以内,自从智能体上线后合并吞吐量翻了三倍。周五的复盘会越开越短,因为实在没什么可复盘的。
直到有一天,竞争对手发布了一个新功能。算不上多巧妙的功能。竞争对手的用户已经在公开论坛上催了半年,团队自家用户在自家论坛上催了几乎一样长的时间。流水线里,没有一个人——也没有一个智能体——注意到这件事。竞争对手上线的消息周二午后落进 Slack 群,会议室一下子安静下来,因为所有人都在问同一个问题:我们这套系统里,到底哪一块本来应该接住这件事?
诚实的回答是:没有这一块。不是有人忘了构建它,而是团队的架构语言里,根本没有一个词指向它。
分层架构(Layered Architecture)、微服务(Microservices)、六边形架构(Hexagonal Architecture)、领域驱动设计(Domain-Driven Design,DDD)——这四种主导软件行业的架构语言,回答的都是同一个问题: 代码该如何切分? 它们没有一个能回答周二下午那个团队问的问题: 这套系统,作为一个组织,靠什么活下去? 这个问题一直有人在回答,只是答案不在架构图里,而在代码之外的人组织里:PM 和 Scrum Master 跑排期,SRE 与 QA 做审计,产品盯外部市场,高管定方向,On-Call 拉警报。架构语言之所以不需要给这些环节命名,是因为组织结构把它们都吸收掉了。
控制论(Cybernetics)五十年前就给这些部件起过名字,只是软件话语后来把这套词汇丢了。AI 智能体系统让这个问题再也回避不下去:当智能体开始承担作业层,需要人覆盖的面积扩展得比人力层能伸展的速度更快。 可生存系统模型(Viable System Model,VSM) 就是最适合用来诊断这个新场景的一面镜子。
控制论简史
这套词汇的成型很快,前后大约四十年,横跨三个学科。Norbert Wiener 1948 年的《控制论》(Cybernetics)把工程师手里"反馈"这个概念,从伺服机构的设计里抽出来,一次性铺到生物学、神经学、社会学和机械工程之上。这本书的副标题——"动物与机器中的控制与通信"(Control and Communication in the Animal and the Machine)——本身就是一种挑衅。Wiener 的主张是:恒温器调节室温所遵循的那套数学,和胰腺调节血糖、市场调节价格、组织调节自身行为所遵循的,是同一套。这种主张当年颇有争议,半个世纪后,已经基本被科学常识吸收。它在操作层面留下的结论是:反馈——也就是把系统的输出导回输入——是任何系统、无论由什么构成,得以维系自身的最基本动作。
Wiener 指出了方向。八年之后,W. Ross Ashby给出了第一道硬约束。《控制论导论》(An Introduction to Cybernetics,1956)提出了 可变性律(Law of Requisite Variety),Ashby 的表述一如他一贯的简练:只有可变性可以摧毁可变性。如果一个系统在受到扰动时可能处于 N 种不同状态,那么它的控制器自身也必须能够给出 N 种不同的响应;任何低于这个数的控制器,都必然存在它无法吸收的扰动。这听上去抽象,其实非常具体。一个只有三档告警级别的监控系统,没法在二十种故障模式之间做出有意义的区分。一道只有五个问题的代码评审清单,没法去评审一个会引入二十种不同风险的合并请求。控制器的可变性必须至少与被控对象的可变性相当,否则这个控制器就是个安慰剂。这是任何调节器都不可能突破的数量地板,无论它内部的逻辑设计得多么巧妙。
Ashby 的律告诉你控制器必须"足够大"。它没有告诉你控制器应该长什么样。这条结构性补充,要再等十四年,才在Ashby 与Roger Conant 合写的一篇短论文里出现。一个系统的良好调节器必须是该系统的模型(Every Good Regulator of a System Must Be a Model of That System,1970)大概是控制论文献里份量最重的"一行标题"之一。论文证明的是:任何具备足够能力的调节器,都必须在自身内部保有一种结构,这种结构必须 镜像 它所控制的系统——也就是说,它必须 是 该系统的一个模型。预先存好的响应表不够。查表式的反应不够。调节器必须在自己内部某处,拥有"被控系统实际是怎么运作的"这件事的某种表示,否则它无法在严格意义上做出良好的调节。Ashby 律回答的是"多大",Conant-Ashby 回答的是"长什么样"。两者合起来,构成任何控制器在形式层面的全部要求——而正如 §5 会展开的,它们也正好是套在大语言模型外面的每一层 harness(外壳)必须满足的约束。
控制论本可以止步于一门数学学科。Stafford Beer从 1950 年代末开始,把它横向引到了一个新场景:组织管理。他的核心问题——一个组织要怎样才算"可生存",才能在环境的持续扰动下保持自己之所以为自己?——其实就是Ashby 的问题,往上抬了一层。1972 年出版的《企业之脑》(Brain of the Firm)第一次完整给出了 可生存系统模型(Viable System Model) ——把任何可生存的组织,分解为五个递归嵌套的子系统,外加一条独立的审计通道和一条独立的警报通道。1985 年的《组织系统诊断》(Diagnosing the System for Organizations)对模型做了细化,并补上了 VSM 真正有用的姿态:VSM 不是一份可以照抄的蓝图,而是一面拿来照组织的镜子——一份关于 哪些部件必须在系统中的某处存在 的清单。Beer 的论断是:缺了其中任何一个子系统的组织,并不是"不健康",而是在结构上注定无法在它尚未吸收过的可变性下继续生存。

图 1:控制论谱系的四部著作。每一部都把前一部触不到的地方往前推一寸——反馈作为最基本的动作;一个系统需要多大的控制;控制要长什么样;以及它怎样在组织层面落地。
控制论问的不是"这个系统由什么组成",而是"这个系统靠什么在干扰中保住自己的身份"。后一个问题,软件架构在过去二十年里基本没有在问——而 AI 智能体系统让它再也回避不下去。
VSM 的五个层级——以及一条 AI 智能体流水线在这五个层级里的样子
VSM 把任何一个可生存组织分解为五个子系统外加两条侧通道。五个子系统构成一条自下而上的纵列——最底层是原始执行,最上面是身份;审计通道横向地盯着其中一个子系统,警报通道则从底端直达顶端,绕过中间所有层级。Beer 的《企业之脑》(1972)和《组织系统诊断》(1985)对这两类结构都做了详细展开。下面把每个层级都拿来过两遍:先看它在传统软件组织里历史上是怎么落地的,再看它在一条跑 AI 编程智能体的开发流水线里长什么样。

图 2:可生存系统模型与痛快通道。每一层左侧给出它在传统工程团队里历史上的角色,右侧给出它在一条跑 AI 编程智能体的流水线里的对应。S3* 画成一条与 S3 平行的侧通道——不是 S3 的下属。痛快通道则是从 S1 直接通向 S5 的纵向警报路径,跨过中间所有层级。
S1 —— 作业(Operations)
S1 是执行单元——真正在干活的那部分。一个可生存系统里 S1 永远不止一个:VSM 假定作业层具备多样性;并且每一个 S1 自身也是一个可生存系统,只是处在下一层递归里。 在传统工程团队里,S1 就是写代码的开发者、跑测试的进程、执行部署的脚本。 在 AI 智能体流水线里,S1 是一次智能体会话——一次 coding agent 的调用,从队列里取走一个工单,产出一个合并请求。每一次会话自成一体,有自己的上下文窗口,最终产出一份可被审视的离散制品。§1 里那个团队的 S1 是健全的:智能体一整天都在交 PR。
S2 —— 协调(Coordination)
S2 这一层管的是不让各个 S1 互相踩踏。用Beer 的语言来说,它的作用是抑制那些共享资源或者必须顺序执行的作业之间的振荡。 在传统工程团队里,S2 体现在分支策略、PR 评审队列、结对编程的协议,以及"不打招呼不能往 main 上推"这种没人明文写但人人遵守的默契里。 在 AI 智能体流水线里,S2 是那一层让多个智能体会话能够并行运行而不互相污染状态的技术隔离:独立的 git worktree、沙盒化的运行时、按请求作用域隔离的数据库 fixture、以及围绕共享写路径的锁原语。§1 里那个团队的 S2 也是健全的——没有它,两个智能体同一时刻碰同一个文件,会留下任何仪表盘都掩盖不掉的合并混乱。
S3 —— 控制(Control)
S3 处理的是此时此地的运作管理:调度、资源分配、监督,以及当某处出错时立刻介入。 在传统工程团队里,S3 就是 Scrum Master 和工程经理那一摊——站会、迭代规划、产能分配、阻塞解除。 在 AI 智能体流水线里,S3 是那一层"决定哪个会话处理哪个工单、以及优先级如何"的逻辑:DAG 计划器、工作分派策略、对长时间未关闭的 PR 进行升级处理的会话分诊。当工程负责人说"我们需要更好的工具来管智能体",他们说的多半就是 S3——§1 里那个团队也确实搭了这一层,是一个把工单分发给当天最合适的智能体的路由系统。
S3* —— 审计(Audit)
S3* 是侧通道,它盯着 S3 自身,专门看 S3 在自己镜子里看不到的那种系统性偏移。 在传统工程团队里,S3* 就是运维侧的 SRE、产品侧的 QA、访问侧的安全审计——这些岗位故意 不 在常规汇报链里。 在 AI 智能体流水线里,S3* 是审计:审计路由系统、审计计划器、审计监督逻辑,看它们做的是不是它们声称要做的——而且要独立于运行这一切的人。S3* 在结构上有一个关键属性,§4 会回到这里:它必须 绕过 S3 自身的渠道才能触达 S3。一份被审计方能改写的审计,不是审计。
S4 —— 情报(Intelligence)
S4 是这套系统中那部分朝外、朝前看的能力:扫描环境、对可能的未来建模,把那些还没人放进 backlog 的事情主动浮上来。 在传统工程团队里,S4 就是产品管理、用户研究、销售情报、客户成功、竞品分析这一组功能。 它很少由单独一个岗位承担,更像是一种 功能——分散在那些以"把团队之外的世界翻译成团队之内的工作"为本职的人身上。在 AI 智能体流水线里,S4 几乎总是不存在。大部分流水线能消化的,是已经躺在 JIRA 里的工单;很少有谁能在系统里安置一个器官,专门去注意" 应该 躺在 JIRA 里却没躺进去"的事。§1 里那个团队对竞品功能的盲视,既不是 S1 出问题,也不是 S3 出问题——是 S4 这一格空着。
S5 —— 政策(Policy)
S5 承载的是身份与目的:那些不可证伪的承诺,说明这套系统 是 什么、 为了 什么。S5 不是规则手册;它更像一部宪法——一小组陈述,定义这家组织是什么类型的组织,提议的行动可以拿到这里来对照衡量。 在传统工程团队里,S5 散落在创始人的发言、公司价值观文档、高管在 All-Hands 上反复强调的几个要点里——对工程师来说,则散落在 AGENTS.md、CLAUDE.md、各类原则文档和架构决策记录(ADR)这类制品里。 轻量级规约框架就是尝试在仓库里给这类承诺安排一个稳定居所的努力之一。在 AI 智能体流水线里,S5 落在任何把流水线的目的写得足够清楚、清楚到智能体可以被期待按它行事的地方。当 S5 缺位时,指标会自动填补真空—— 我们交付得很快 会变成实际上的身份,因为那是仪表盘唯一能度量的东西。
痛快通道(Algedonic Channel)
痛快通道是一条从 S1 直接通到 S5、绕开 S2/S3/S4 的纵向通路。Beer 取名时借用了希腊语 algos(痛)和 hedone(乐)——这是警报通路。它存在的理由是:有些信号太紧急、或者在系统层面太重要,以至于走不通常规汇报链。 在传统工程团队里,痛快通道就是 On-Call 的告警页、安全事件的升级路径、客户成功直接打进 CEO 邮箱、绕开三层经理的危机电话。 在 AI 智能体流水线里,痛快通道是那一层在"系统本来没设计要识别、却被它意识到了的东西"出现时拉响警报的机制——一类没有指标覆盖的故障、一种没有 S4 在盯着的外部信号。§1 里那个团队没有这条通道;"我们交付的东西"和"用户真正需要的东西"之间的裂缝,本来无论如何都会出现,但一条工作着的痛快通道,本可以在竞品发布的消息落进 Slack 之前很久就把它浮上来。
三条反直觉的诊断启示
上面的走读给了你一套词汇。下面这三条诊断启示,则是在你拿到这套词汇之后, 实际 会在真实软件组织里看到的东西。三条单看都不戏剧。但合起来,它们能解释大部分工程负责人已经学会识别、但还没有学会 命名 的失败模式。
1. S4 缺位是常态,不是异常
多数软件组织在没有完整 S4 的情况下运行,相当一部分连完整的 S3 也没有。"这套系统对自己的外部环境毫无觉察"不是缺陷,而是常态。原因是 S4 贵——它需要一群以"看团队外面的世界、把所见之物翻译成可执行提案"为全职的人。预算一旦紧张,S4 是第一个被砍掉的环节,因为它产出的东西,在它消失之前,都不会出现在任何仪表盘上。
§1 那个场景是一个干净的例证。这个团队 S1、S2、S3 都有,审计也以某种形式存在,身份是默认存在的。唯一缺的,是一个朝外看的器官。竞品功能在公开论坛上摆了半年,团队里没人把"看到这件事"当成自己的工作。这并不少见——业内对失败 AI 智能体项目的调查显示,"环境盲视"在失败原因清单上一直靠前,2026 年更宽阔的智能体生态版图里同样能看到相同的形态。多数 AI 智能体流水线只能消化已经躺在 backlog 里的事;很少有谁能去注意"本来应该躺进 backlog、但没躺进去"的事。如果这篇文章只剩一句话值得记住,那就是这一条: S4 缺位是软件组织最常见的失败形态,AI 智能体流水线默认继承了这条特性。
2. S3* 无法被 S3 吸收
审计通道必须 沿着 S3 跑,而不是 穿过 S3 跑。一旦一条审计信号必须穿过它本来要审计的子系统才能到达观察者,它就不再是审计——它变成自报告。这就是为什么运维层的 SRE、产品层的 QA、访问层的安全审计,会被刻意部署在工程汇报链 之外——Google 自己在 SRE 转型实践笔记里就明确写过:"SRE 与开发组织共享目标,但在 SVP 及更高一级之前,常常各走各的汇报线"——不是因为这些岗位的经理想要自己的仪表盘,而是因为审计这件事在结构上要求独立。那些把"SRE 划到工程经理麾下"或者"安全划到平台团队"的做法,做的团队,半年后通常会发现,他们以为自己有的那份审计,本质上是一份带额外人头编制的自报告。
在 AI 智能体流水线里,这条约束同样成立,而且更紧。审计智能体的系统不能与智能体走过的路由系统共享状态。审计计划器的系统不能由计划器配置。审计 prompt 演变方式的系统,必须从一个智能体层根本碰不到的写路径上读取。这些都不是 nice-to-have。一份审计子系统如果连间接都能被被审计层改写,那它就是安慰剂——而安慰剂比"压根没有审计"更糟,因为它给已经存在的问题提供了掩护。
3. S5 是不可证伪的承诺,不是 if-then 规则
"我们是一个低延迟系统"是 S5。"p99 延迟超过 100 毫秒就告警"是这条承诺在 S3 层面的一次具体落地。两个层级不可互换,下一节会把这种差异讲透。承诺说的是这套系统 是 什么;规则说的是一个具体的可观测检查项。一项承诺可以在任何一条具体规则失败时继续成立;一条规则没法在底层情形变化时继续成立。把这两者混为一谈——用规则替代承诺——是任何试图"把价值观运维化"的组织最常犯的架构错误。这也是那些建立在硬性规则内容过滤之上的 AI 治理框架反复掉进的坑;下一节会把"为什么这条路在结构上注定走不通"讲清楚。
为什么"投影"不是"模型"
第三条反直觉的启示——S5 的承诺不是 S3 的规则——乍听起来像是风格建议,是讲道理的人之间可以有不同看法的事情。其实不是。控制论的两条结果加上经济学的一条结果合在一起,就足以说明:只靠规则来运行一套系统、而没有底层承诺,这不只是糟糕的实践,而是在结构上根本不可能成立。
两条定理,一组约束
§2 已经分别引入了这两条结果。理解它们最好的方式是放在一起看。
Ashby 的 可变性律 定出数量地板:控制器的可变性至少要不小于被控对象的可变性,否则总会存在它无法吸收的扰动。 Conant-Ashby 定出结构地板:任何足够有效的控制器,其内部结构必须 镜像 被控系统——按定理的精确表述,它必须 是 那个系统的一个模型。Ashby告诉你控制器要多大。Conant-Ashby 告诉你控制器要长什么样。一个体量够但结构空洞的控制器,败给 Conant-Ashby;一个结构合理但体量不够的控制器,败给Ashby。两条约束必须同时满足,单独任何一条都不够。
模型 vs. 测量
想看清 Conant-Ashby 到底要求什么,最干净的入口不是形式化定义,而是三件日常物事。
体重秤上的数字,是身体成分的一种投影。 你踩上秤,数字往下走,镜子里的轮廓往往没什么变化。秤是有用的。但秤不是身体成分。
薪资,是财务自由的一种投影。 两个工程师拿同样数字的工资,他们各自的自由度可能差到天上去——债务多少、生活成本几何、被动收入多少、对自己时间的支配程度多少。薪资是有用的。但薪资不是自由。
工龄,是经验的一种投影。 在一家公司待十四年,可能是十四年的复利成长,也可能是第一年的经验重复了十四遍。工龄是有用的。但工龄不是经验。
三个例子里的模式是同一个:一个数字,把一个有结构的对象压缩到单一一根轴上。这个数字是真实的,是有用的,并且 不是它压缩的那个对象。我们把"保留系统形状"的那种压缩,称为 结构压缩(Structural Compression) ;把"把系统拍扁到单一一根轴"的那种压缩,称为 投影压缩(Projective Compression) 。两种压缩都有用。出错的地方,是把投影 当成 结构来对待。
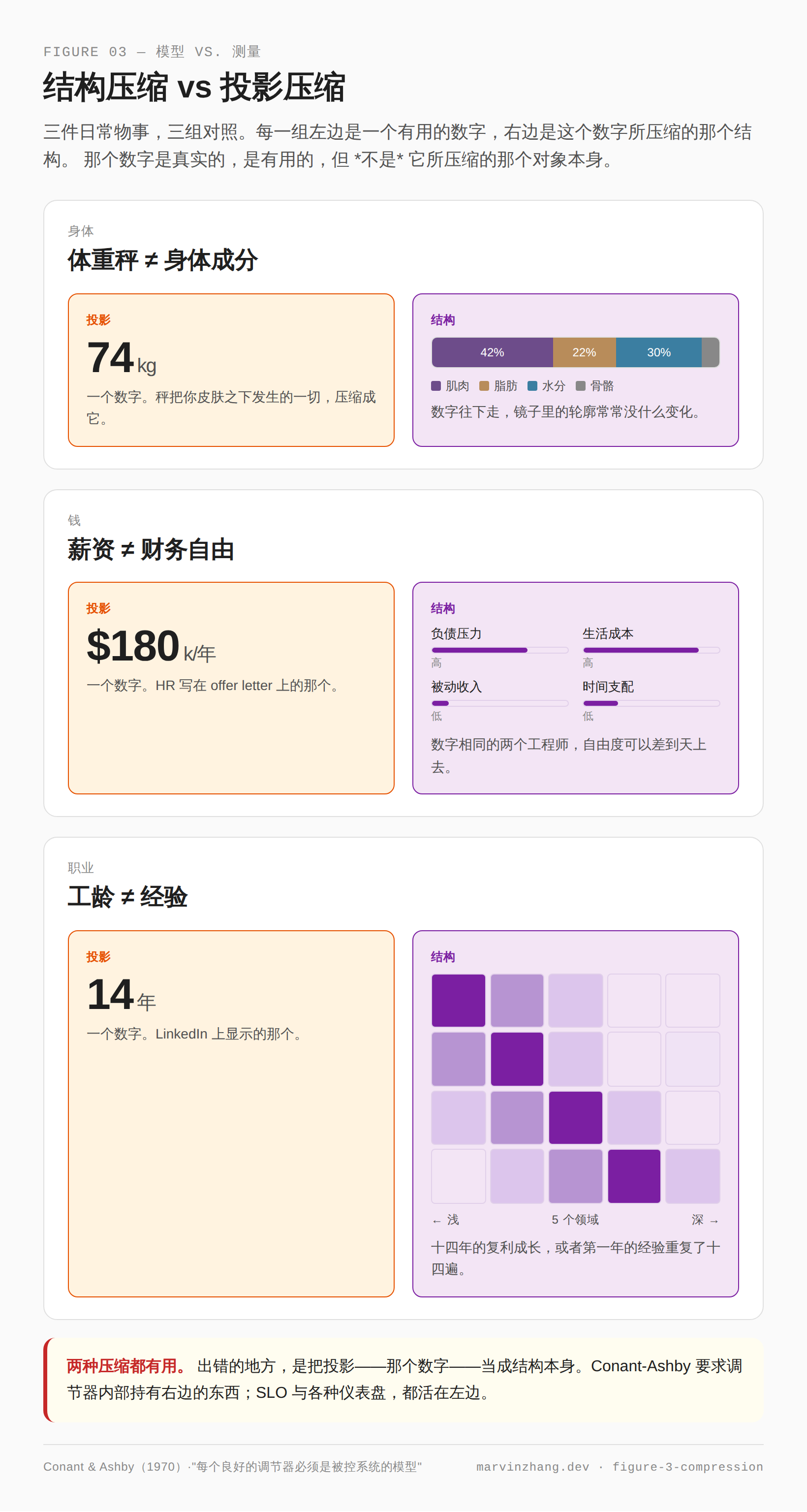
图 3:身体、钱、职业——三件日常物事,每件都以投影(左:单一数字)和结构(右:那个数字所压缩的对象)两种方式呈现。结构是控制器真正能调节的那个东西;投影则是仪表盘上展示出来的那个东西。
Conant-Ashby 用这套语言说的就是:调节器内部持有的,必须是被控系统的 结构压缩——而不只是某种投影。一条由体重驱动的控制环路,不是身体成分的调节器。一套由薪资驱动的管理系统,不是财务自由的调节器。一套由工龄驱动的职级系统,不是经验的调节器。而——预告一下这一节的回报——一套由 SLO 仪表盘驱动的软件系统,不是 它本身存在意义 的调节器。
Goodhart 定律:有名号的失败模式
投影驱动的控制为什么会失败,这件事是有名字的。Charles Goodhart在 1975 年一篇研究英国货币政策的论文里指出:任何一条央行试图用来做控制的统计规律性,一旦政策开始去推它,它就倾向于失效。Marilyn Strathern在 1997 年一篇关于大学审计文化的文章里给出了那个广为流传的表述——当一个度量变成目标,它就不再是一个好的度量。
每个团队过去十年里一直在和它共处的那些硬性工程规则,都是教科书级别的Goodhart陷阱。
- "测试覆盖率必须超过 80%" → 工程师写出
assert(True)把这条线抬上去;最后被部署到生产环境的,就是assert(True)。 - "p99 延迟必须低于 100 毫秒" → 慢请求被采样剔除、被边缘丢弃,或者被路由到一条 SLO 更宽松的路径上;仪表盘绿了,用户依旧在等。
- "每个 PR 至少两个评审人批准" → 评审人互相盖章;策略满足了,代码没人读。

图 4:一条规则出于善意被定下(每张卡片的顶端)。工程师围绕规则做优化(左下)。最终上线的,是一块绿色的指标加上一个没动过的底层问题(右下)。这是投影一旦被当作目标就在结构上必然出现的模式——业内多年来反复在处理的一个现象。
这些规则没有一条是设计得糟糕。它们都是投影——是把团队真正在意的那种底层属性,压缩到一根轴上的单值表示——被当成目标在使用。一旦投影变成目标,整个系统就会针对这个投影做优化,而这种优化恰恰摧毁了投影本来作为测量的价值。指标被推得越用力,底层属性偏离得越远。
S5 不能被 S3 替代
为什么 S5 不能被 S3 替代?现在可以从两个独立的角度同时看到答案。Conant-Ashby 不允许:S5 是关于"这家组织 是 什么"的结构压缩;S3 是这个模型在某个时刻、沿某根轴的一次投影压缩。一个只有投影、没有模型的控制器——按定理直接推论——做不出良好的调节。Goodhart会惩罚任何想绕开这一点的尝试:任何试图只用投影来运转的组织都会发现, 瞄准投影 这件事本身会摧毁投影的信息价值。指标越被用力推,底层属性偏离得越远。
这件事对 AI 智能体系统的含义是双倍尖锐的。语言模型在它目前的形态下,并不在内部持有一个关于"它被部署去控制的那套系统"的模型——这是一次 Conant-Ashby 违例。常见的补救手段——静态规则集、内容过滤器、输出校验器、行为策略一层套一层——则是"把投影当目标",一次Goodhart漏洞。两种失败模式都不是偶然的,是结构性的。Harness 工程做得好的时候,造的是模型而不是墙:它构造的控制器,其内部结构镜像被控系统;它把指标当作 诊断读数 而不是优化目标。VSM 是 Conant-Ashby 在组织层面的样子。Harness 工程是 Conant-Ashby 在 AI 系统层面的样子。两者回答的都是同一个问题——那个问题至今还没被这个领域学会大声问出来。
- AI 智能体:工程高于智能——本文论点所建立的架构性框架。
- AI 的最后一公里是基础设施,不是智能——相邻的论证:真正的瓶颈到底在哪里。
- 绘制 2026 年 AI 智能体版图——智能体系统当下处境的更宽阔背景。
- 你的代码评审为什么失效(以及怎么修)——"双评审Goodhart陷阱"的深入讨论。
一项正在进行的工作
我目前正在把这套框架应用到自己的一个项目——Onsager——上,它要做的是为软件开发场景搭建一类 AI 智能体流水线。一路走下来最大的收获,并不是验证了 VSM 的完整性,而是这套模型让"缺什么"变得非常显眼。两个层级尤其如此——S4 和痛快通道,也正好是最常被人轻描淡写为"用不到"的两个——它们一旦缺席,迟早会以 §4 描述过的那些失败形态浮出水面。这件事还处在很早期,我学到的大部分东西仍然只适用于自己当前的语境,但 VSM 在诊断阶段已经足够有用,所以我想在实施细节那篇文章落地之前先把它标出来。具体的实施工作,等到能写出来再单开一篇。
当系统的部件本身开始携带目的,我们需要的不是一种新的架构范式,而是一门被遗忘了很久的旧语言。