实战数据科学: 如何利用 sklearn 轻松上榜 Kaggle 入门 NLP 竞赛

引子
Kaggle 是一个面向数据科学家、机器学习工程师和数据分析师的在线社区和数据科学竞赛平台,上面有很多带有奖励的数据科学竞赛(Competition)以及数据集(Dataset)。Kaggle 社区在数据科学领域非常出名,很多互联网业界大厂也在上面发布有奖竞赛,竞赛金额从几万到百万美元不等。本文介绍的是最近参与的 Kaggle 一个入门 NLP 竞赛,没有现金奖励,但可以学习到 NLP 相关的机器学习知识。
竞赛简介
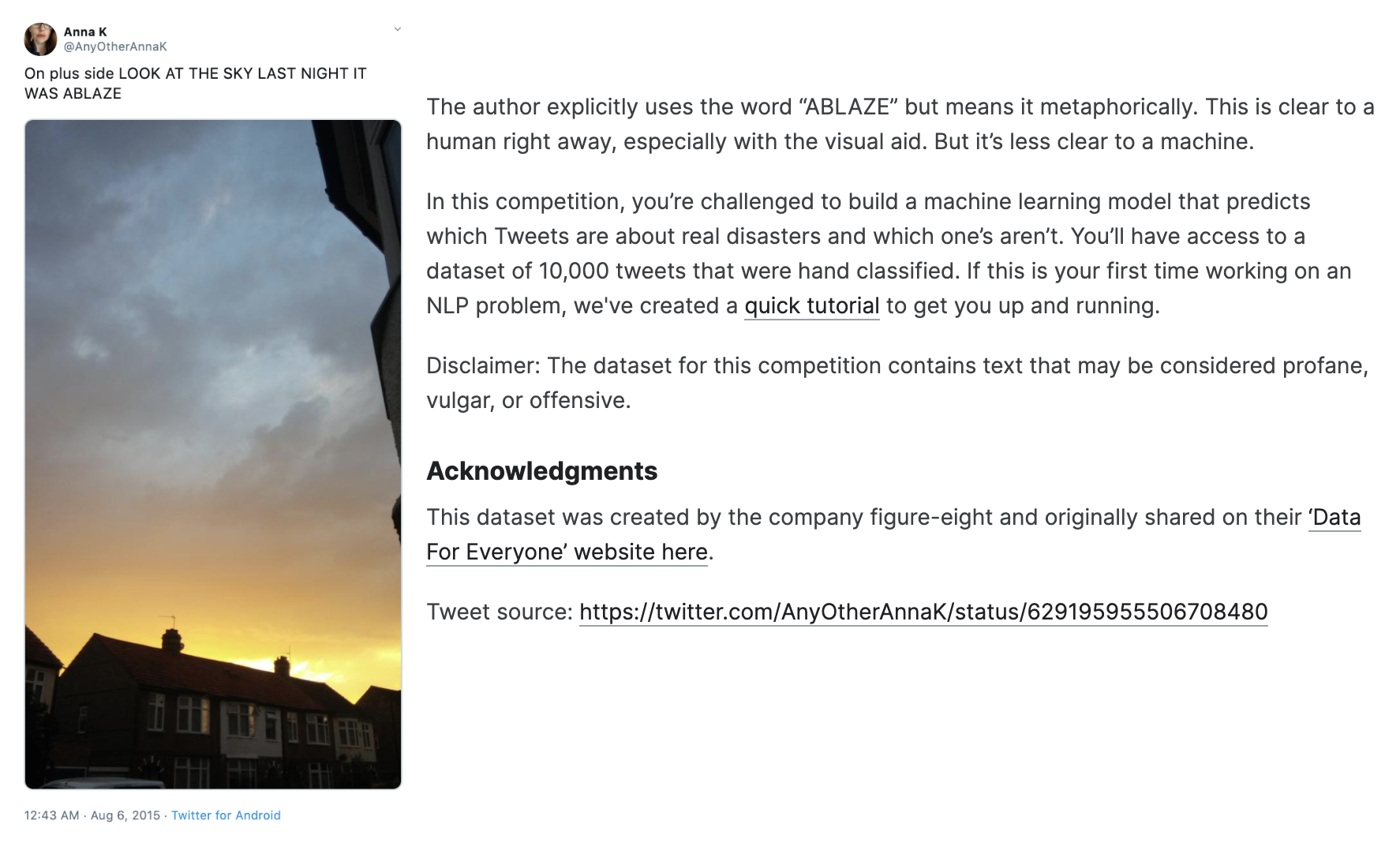
这个数据科学竞赛是希望竞赛参与者通过给定 Twitter 上的一条推文(Tweet),来判断推文是否是关于一场真实的灾害(Disaster)。下图是某一条推文的情况,推文中有 "ABLAZE"(燃烧的)关键词,预示着该推文是说有房子燃起来了。
下载数据集
首先,我们需要下载分析预测的数据集。我们到官网上的数据集网址 Natural Language Processing with Disaster Tweets | Kaggle,点击 Data 标签,拉到页面右下方点击 Download 按钮。
下载下来的数据集有三个文件:
train.csv: 训练数据,用来分析训练的数据集,包含所需的训练数据样本以及正确预测值target(1 表示命中,即该推文是关于灾害的;0 表示不为灾害);test.csv: 跟训练数据类似,有推文的内容,但被隐去了target,这也是需要提交到 Kaggle 来参与预测竞赛的测试样本;sample_submission.csv: 提交的样本格式,其实就是test.csv中的id列和预测出来的target列。
探索数据集
虽然本次 NLP 任务要分析的是非结构化数据集,但我们还是可以利用 Pandas 库来查看一下数据集长什么样子。
在 Jupyter Notebook 中,我们先引入 Pandas 库来读取训练和测试数据集。
from pandas import read_csv
# load and preview training data
df_train = read_csv('train.csv')
df_train
...
# load and preview test data
df_test = read_csv('test.csv')
df_test
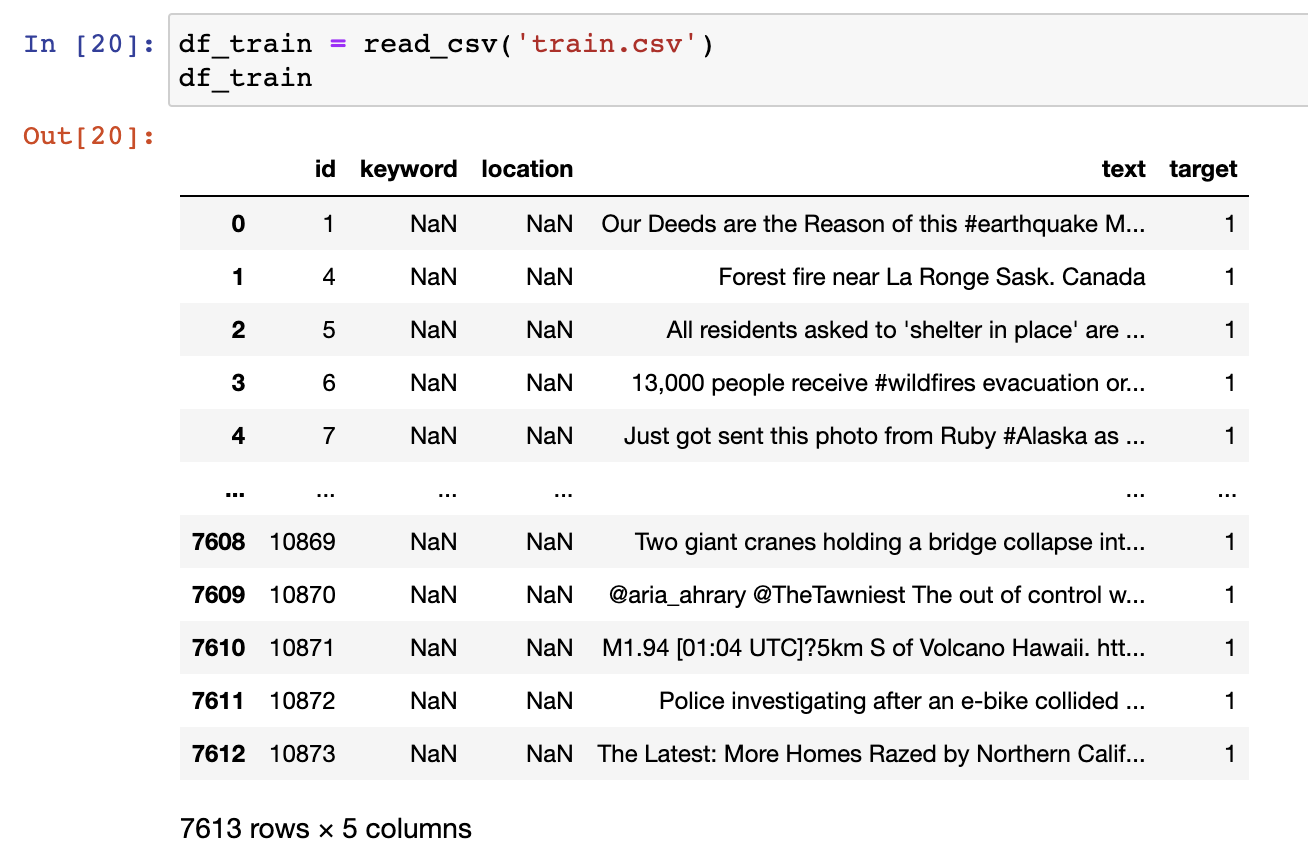
可以看到,似乎大部分内容在 text 列中,我们进一步看看 target 中是如何分布的。
# preview target column
df_train.target.value_counts()

有将近不到一半的推文被判断为了跟灾害有关,即为 1。
我们再来看看,其他两列 keyword 和 location,看看空值 NaN 大概有多少。
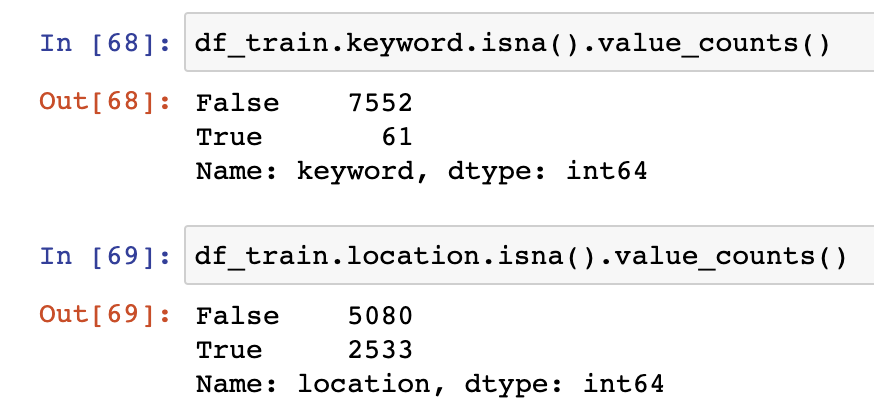
看上去空值似乎并不是很多。
转换文本数据
为了后面的建模预测,我们需要将非结构化的文本数据转化成结构化的高维度数值数据。这其中我们需要用到的就是 Scikit-Learn(简称 sklearn)中的 TfidfVectorizer。这是一个常用的文本特征提取工具,用于将文本数据转换为可供机器学习算法使用的向量表示。其中用到的经典算法叫 TF-IDF,能够优化文本的关键词权重。简单来说,就是当文本出现的频次越高,例如 "this", "the", "a",就说明越不重要,因此权重应该越低;相反,如果某个词只出现在某一个或某几个文档中,即非常罕见,就说明其更有特别之处,因此权重应该更高。而 TF-IDF 正是有这样的特性。

在 Python 中调用 TfidfVectorizer 来向量化文档也非常简单。
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
...
# vectorizer
vec = TfidfVectorizer()
# fit vectorizer
vec.fit(np.concatenate((df_train.text, df_test.text), axis=0))
这里我们将训练数据和测试数据的 text 列合并喂入 TF-IDF 向量化实例 vec,它会自动将每一条文本进行分词并运行 TF-IDF 算法。
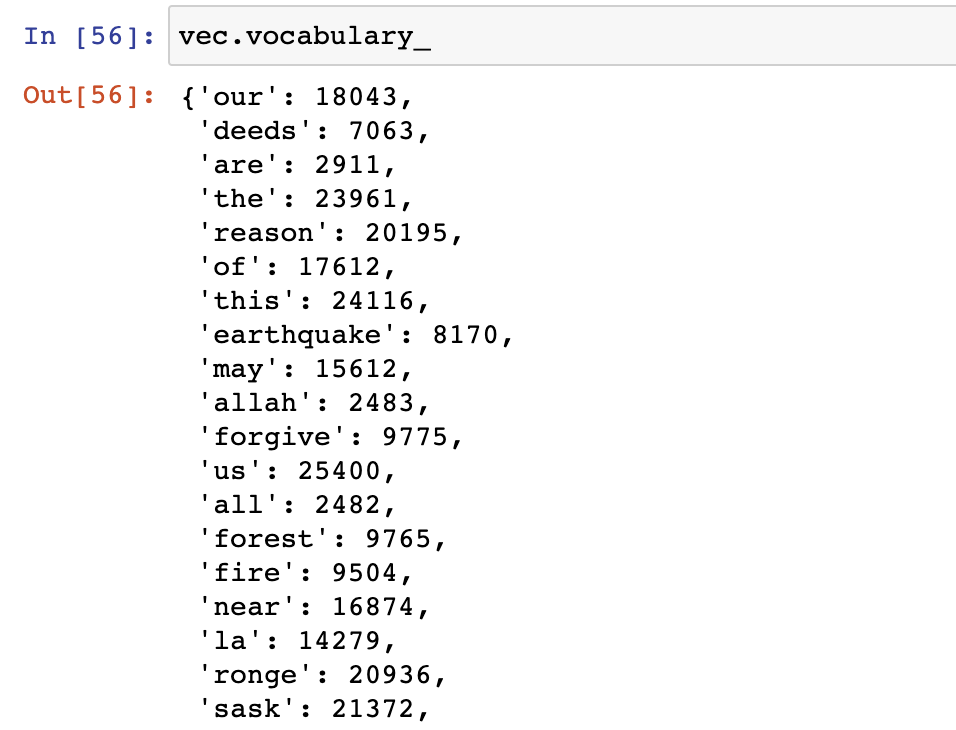
我们可以看一下其中用到的词汇。
# preview vocabulary
vec.vocabulary_
接下来,就是转换文本为向量了。
# transform texts into vectors
X_train = vec.transform(df_train.text)
我们查看一下 X_train 是什么。
# preview X_train
X_train

其实 X_train 就是 7613x27922 的稀疏矩阵,其中 27922 是该数据集的维度,即有多少个词语来表示该推文。这也充分说明了文本数据是高维度的数据。
训练评估数据
数据准备好了,我们就可以开始训练并评估训练数据集了。
首先,我们定义一下目标向量。
# target vector
y_train = df_train.target
然后,我们利用 sklearn 中的逻辑回归分类器 LogisticRegression 来进行分类预测。逻辑回归(Logistic Regression)是一个线性模型,通常用于二元分类(Binary Classification)。使用它也非常简单。
from sklearn.linear_model import LogisticRegression
...
# logistic regression classifier
clf = LogisticRegression()
# fit classifier with training data
clf.fit(X_train, y_train)
这样,我们就得到了训练好的分类器。
接下来,我们利用 sklearn 的评估工具 classification_report 来评估一下这个分类器在自身数据集上的表现(Performance)。
from sklearn.metrics import classification_report
...
# predict with classifier
y_train_pred = clf.predict(X_train)
# classification report
report = classification_report(y_train, y_train_pred)
print("Classification Report:")
print(report)
运行完成后,我们可以得到分类器的表现报告。
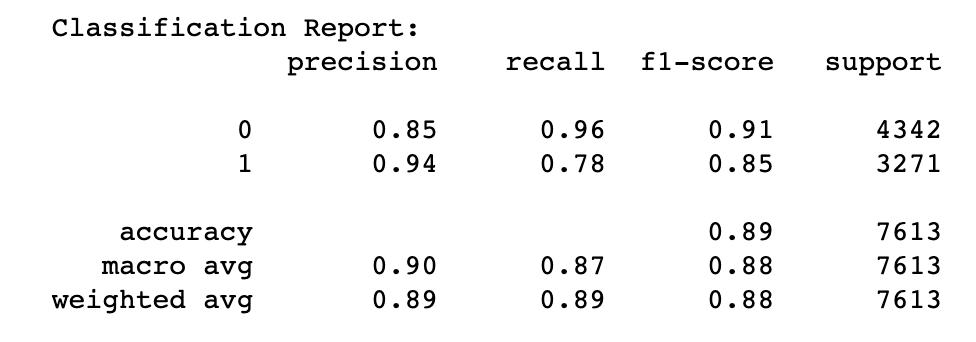
可以看到,在自身数据集上的表现还是不错的,准确率能达到 89%。
提交预测
接下来,我们需要提交预测,要做的只是将分类器在测试数据集上运行一遍得到预测值,并生成对应的 CSV 文件,上传到 Kaggle 竞赛即可。
# transform text to vector (test data)
X_test = vec.transform(df_test.text)
# predict target (test data)
y_test_pred = clf.predict(X_test)
# assign target column (test data)
df_test['target'] = y_test_pred
# generate submission csv file
df_test[['id', 'target']].to_csv('submission.csv', index=False)
然后,我们将生成好的 submission.csv 文件上传到 Kaggle 竞赛,就可以立即得到评分结果。
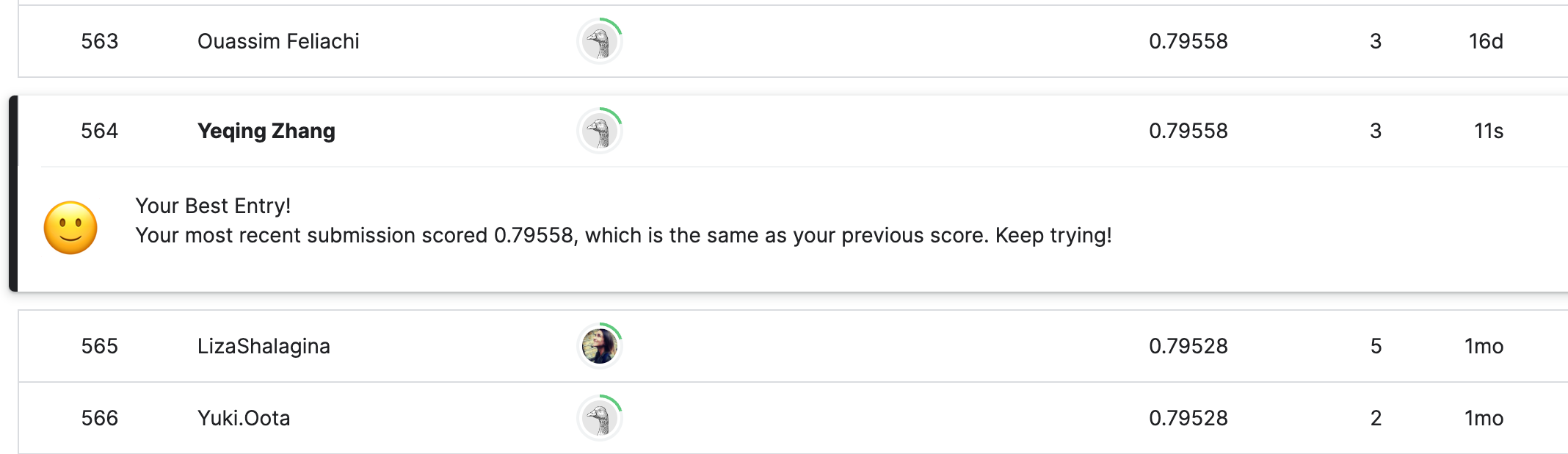
很棒!我们得到了 0.79558 的准确率,排名大概 50%,相当于打败了一半的对手。
总结
通过简单的用 TF-IDF 文本向量化以及逻辑回归分类器作用于推文数据集,我们得到了大约 80% 的准确率,这已经相当不错的成绩了!要知道,我们还有一些字段没有使用呢。如果要提高结果,应该需要用到 keyword 这个字段以及推文中的 Hashtag,即类似 #wildfire 之类的标签信息,这些在本次竞赛尝试中都没用到。笔者尝试用了逻辑回归以外的分类器,例如朴素贝叶斯分类器,在训练集上可以,但测试数据集上评分不佳。Kaggle 上还有很多其他的有趣的竞赛,感兴趣的读者可以去试着参加。
社区
如果您对笔者的文章感兴趣,可以加笔者微信 tikazyq1 并注明 "码之道",笔者会将你拉入 "码之道" 交流群。